



































 ディープラーニング技術によって、学生の発言内容に「提案」「質問」といった分類タグをリアルタイムに付加。音声チャットにも適用が可能だ。
ディープラーニング技術によって、学生の発言内容に「提案」「質問」といった分類タグをリアルタイムに付加。音声チャットにも適用が可能だ。
東京工科大学は、ディープラーニング技術を用いたオンライングループ学習支援システムを出展する。プロジェクト名を「 ディープラーニング・対話・まなびプロジェクト」と呼び、「ディープラーニング技術による教育ビッグデータの分析・可視化手法の開発・評価」と呼ぶプロジェクトから派生して生まれたもの。
「ディープラーニング技術による教育ビッグデータの分析・可視化手法の開発・評価」は、日本でも最近注目されている課題解決型学習(PBL=Problem Based Learning)の支援を目的に開発された。PBLとは、授業の進め方の新しい手法で、教師が教えることを聞くのではなく、学生同士がディスカッションを通じて自主的に課題を解決しようというもの。その会話のやりとりの中で、学生の積極性や解決へ向けた貢献度などを評価、指導していく。この評価のもとになる会話の分析にAIを活用しようという試みが「ディープラーニング・対話・まなびプロジェクト」だ。
具体的には、学生間の対話(チャットデータ)をテキスト化し、リアルタイムで自動分類(タグ付け)をすることで、データの統計的な定量的分析と、定性的な発言内容の解析をする。開発した手法はSNSやコールログの高精度の解析などへの応用が期待できる。
■大量のeラーニング会話データを質的に分析
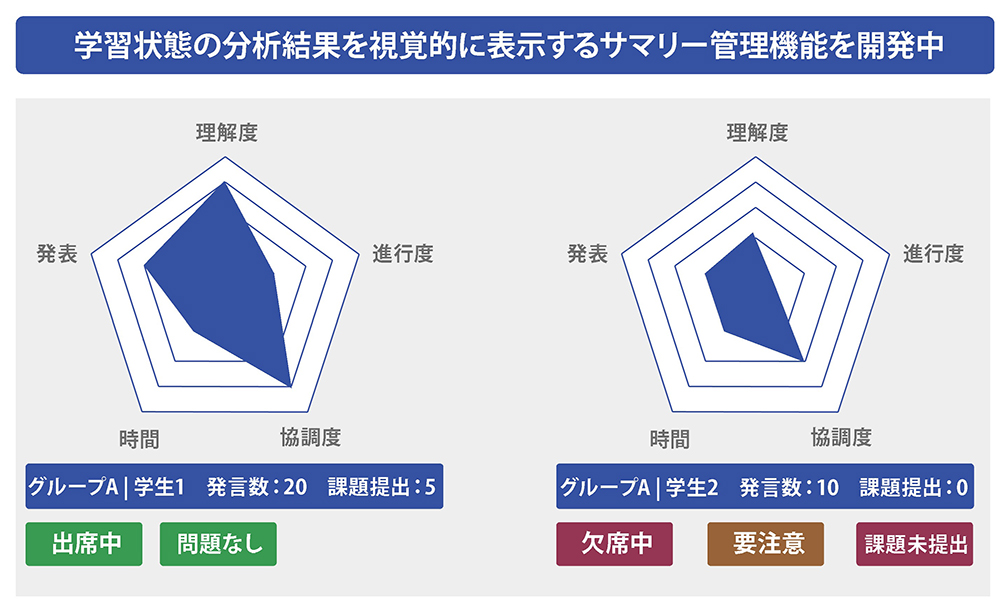 分類タグをもとに、発言の量だけでなく、「理解度」「協調度」といった質的な評価を開発。
分類タグをもとに、発言の量だけでなく、「理解度」「協調度」といった質的な評価を開発。
同研究の代表者、東京工科大学教養学環 大学院 バイオ・情報メディア研究科の稲葉竹俊教授は、開発の背景について次のように説明する。
「当学では、2010年からオープンソースのeラーニングプラットフォーム『Moodle』をもとに、協調(グループ)学習システムを構築しています。これは、オンライン上でテキストベースでコミュニケーションができるグループ学習用チャットです。1つの授業で数百人の学生がグループを形成し、授業時間や学外で議論するため、非常に大量のチャットデータが記録・蓄積されています。これを教員がすべて読み込んで評価、指導するのは困難なため、大量のデータをどう扱うかというところから開発が出発しました」
「量的なデータ分析に留まらず、細かい議論の詳細、推移を適確にとらえるにはどうしたらいいかという質的な評価を高い精度で実施しようと考えました。現状の議論の分析とともに、事後に議論全体を分析するという二つの機能を持ちます。AIが、会話の一つ一つに、それがどういう意味を持つのかを表す『ラベル』をあてていきます。ラベルとは、メタデータ、タグの一種ですが、社会学におけるアンケート分析や文化人類学の調査などで用いるもので、調査の細かいデータを質的に解析するための手法です」(稲葉氏)
■会話の種類を16通りに分類
ラベルは会話の種類やカテゴリーによって、体系的に整理されている。現在、ラベルは提案、質問、回答、議論、雑談といった16種類ある。すべての会話にラベルをつけることによって、一人一人の学生の発言傾向や、活動の度合いを細かく見通せるようになったという。分析結果をリアルタイムで視覚的に表示できるため、 議論が活性化していないグループに注意をするなど、会話の最中に指導をすることも可能だ。
この会話のラベルづけを深層学習で行うことにより、大量のデータをより高い精度で分析することが可能になった。 会話のラベル化に用いた深層学習のためのニューラルネットワークは「seek to seek」と名付けられており、東京工科大学大学院バイオ・情報メディア研究科の柴田千尋博士が開発を担当した。 柴田氏は同研究の共同研究者の一人。
■国際的な学会で高い評価
 研究論文は、eラーニングの学会 eLmL2017(The Nith International Conference on Mobile, Hybrid, and On-line Learning)で最優秀論文として表彰された。
研究論文は、eラーニングの学会 eLmL2017(The Nith International Conference on Mobile, Hybrid, and On-line Learning)で最優秀論文として表彰された。
AIやビッグデータの開発に用いられるプログラミング言語Pythonを用いており、ライブラリーにはGoogleが公開した人工知能ライブラリーTensorFlowなどを使用しているという。
学習は最初に人手によってラベルづけをした会話を訓練例としてラベルごと読み込ませ、その上で、今度はラベルのない会話のラベルづけをさせる。大量の訓練例を読み込ませることで知識を獲得し、ルールを自動的に推論し、ラベルづけの精度が向上していく。
ラベルの自動化は、これまでも、機械学習の手法による研究があったが、深層学習では初の試み。従来の機械学習と比べ、高い精度を実現したことが評価され、今年3月にフランス・ニースで開催したeラーニングの学会 eLmL2017(The Nith International Conference on Mobile, Hybrid, and On-line Learning)で最優秀論文として表彰された。
■音声会話のラベリングにも挑戦
 左から、稲葉氏、柴田氏。
左から、稲葉氏、柴田氏。
柴田氏は今後、ラベリングに加えモデルをもとにした質的な評価もAIで実施していくことを研究中という。「ある発言に偏っている。ある人だけが発言している。など、リアルタイムに議論が活性化していないグループに対してリアルタイムに介入をするとき、 非常に上手くいったグループをモデル化する事が必要になります。そのモデルとの乖離を計算することで、問題のあるグループを抽出できます」
柴田氏は、さらなる研究ステップとして音声のラベリングをあげる。「口語は文字と比べ、構文が間違えていたり、途中でとぎれていたりすることが多いため難しいテーマです」音声による会話のラベルづけができれば、電話応対などのコールログをAIで質的に評価できるようになる。
■社内グループウェアやSNSでの活用めざす
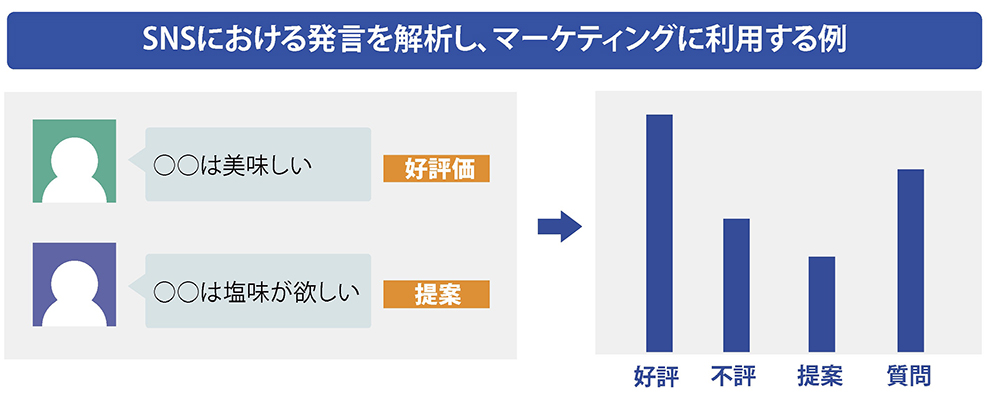 学習評価だけでなく、社内のグループウェアやSNSなど、さまざまな会話の評価に利用できる。
学習評価だけでなく、社内のグループウェアやSNSなど、さまざまな会話の評価に利用できる。
稲葉氏はこうした分析手法が「学習評価だけでなく、社内グループウェアや、SNSなど、さまざまな会話の評価に利用できる。音声に対応できるようになれば、メーカーの電話応対などのコールログや商品評価などの会話を質的に評価することができる」と話す。
「大学で行われている議論には、会話の要素が濃縮されており、他の会話への応用はうまくいくのではないかと考えている。今後は、現在の16のラベルから、より複雑なラベルの体系の構築を進めている。社会次元、議論次元、タスク次元、コーディネーション次元など、見方を決めて、その下にラベルがぶら下がるような構造だ。これにより、より深い議論の質的な分析が可能になる」(稲葉氏)
「今後は、企業との共同研究を経て、ニーズに適したラベルの構造を開発していき、AIを用いた新たなサービスにしていきたい」と稲葉氏は話す。「CEATECのブースでいろいろな要望をお聞きしたい」(同)
東京工科大学
- 展示エリア
- 社会・街 エリア
- 小間番号
- C029
- URL
- http://laweb.cloud.teu.ac.jp/
- 出展者詳細
- http://www.ceatec.com/ja/exhibitors/detail.html?id=9580












































